
As more and more industries adopt ML and data as a strategy and part of the overall software engineering architecture. Data scientists will need to work and interface with software engineering practices to be able to not just model but deploy their models. This is especially going to be true for legacy industries where most systems will be old.
Thus understanding software engineering best practices, challenges and issues associated become necessary for data scientists as well. There are already roles in the industry going as machine learning engineers. They can code at an SDE level but at the same time understand machine learning and best practices on both ends.
Besides these, even for data scientists. An understanding of software challenging and working with legacy code etc is increasingly important to understand all aspects of the project and estimate the challenges there. Understanding software engineering for data scientists is, therefore a key part of the data scientist toolkit.
Machine Learning Vs Software Engineering Differences
Machine learning by nature deals with stochastic aspects. Allowing us to build systems that can work on new data. This is the key difference when compared against typical deterministic software systems. Where the logic is more well defined, unlike machine learning where it can be evolved and modified as we learn.
Testing and Logging Code

This is quite great from building a complex logic point of view. Allowing us to codify and modify very complicated logical steps. This can be very difficult for the typical software business logic. This same benefit presents a huge challenge when running machine learning models in production making testing very difficult. This is a great blog and resource on different types of tests and how to structure them here. This is another thread on working with 200K worth of spaghetti code.
- Unlike typical unit tests, your new tests need to be able to take stochastic outputs. Even the logs will need to designed and though through differently.
- Testing and logging are the two key aspects to maintaining a large scale enterprise quality project.
Legacy Systems
A legacy system in my definition is any piece of software that has been running for a long time, is responsible for a key profitable unit of business. It would not be maintained if not for making money. Most of the major developers are either not available or can’t be reached easily.
Most of the issues mentioned when working with legacy code are around not having test cases that make modifying the code challenging besides not having a sufficient amount of documentation to start with. These issues are well discussed in this StackOverflow thread.
Working Effectively with Legacy Code
Some common suggestions and approaches are these though depending on the requirements, you can use the plain old cowboy style where the end customer becomes the tester for the product.
- Unit Tests: Unit tests will help us know what the expected value of a code functionality is.
- Refactoring: This will allow us to start to refactor the code piece as per need. Since, we have the unit tests, we should be able to modify the code pieces knowing we know what the output should look like.
- The refactoring should involve breaking large classes into smaller ones.
- Reuse similar pieces of code and make the whole thing more readable.
- Document the stack flow and the logic.
Working Effectively with Legacy Code

Lots of these codebases will have the need for additional functionality or services and this would further become a challenge when it will need machine learning components or modules added.
All of this will require the need to write tests and do extensive documentation and verify any existing ones. Irrespective of the type of the system, ML or otherwise. You will need to learn to work with old code bases and most of the concepts and learnings are similar.
While a bit too extreme, it’s indeed the case with putting data science models or plans into production. Machine learning is needed when a firm has lots of data and a proven business model/equation to optimise for. This is especially a challenge for early-stage firms which are better off sticking with basic startup analytics.
For mature organizations and growth-stage startups, productizing machine learning throws up a gambit of risks in terms of execution. This includes hidden costs and plausible engineering constraints, which can make complex models prohibitive.
Production Machine Learning 101
The basic requirement to get started on the production side is to have a specific problem statement along with the model ready.
- We know the features to use
- The model to use
- The metric, we are using to measure model.
The simplest model in production uses an offline training approach which we update with a specific training interval. This could be a day, week or longer. The time interval depends on the business need which further depends on how quickly the new data changes and affects model dynamics.
Data Bases and Pipelines
- Databases with data pipelines and scheduled updates.
- Ensure indexation and keys (Primary and Foreign)
- Specific modelling table with the necessary features. This will allows us to pull the data into RAM (Pandas Data Frame) and start modelling.
- Understand the difference between transactional and analytical databases.
Servers & Frameworks
The server is an EC2 instance in this context and RDS(OLAP) for databases. Cookie Cutter Framework is useful to be able to structure the workflows. Splits the entire flow into.
- Data: Temp data sets can be saved as CSV files
- Features: On the fly feature generation
- Modelling: The modelling modules go here, this includes any kind of un-supervised steps such as clustering as well
- Visualization: Extra module to produce, graphs and any other outputs from the reports generated
There is another section for Jupyter Notebooks which I prefer to keep running through the screen(Linux). Can tunnel into the server through a local machine to run any ad-hoc analysis. The notebooks are always up and fast to use.
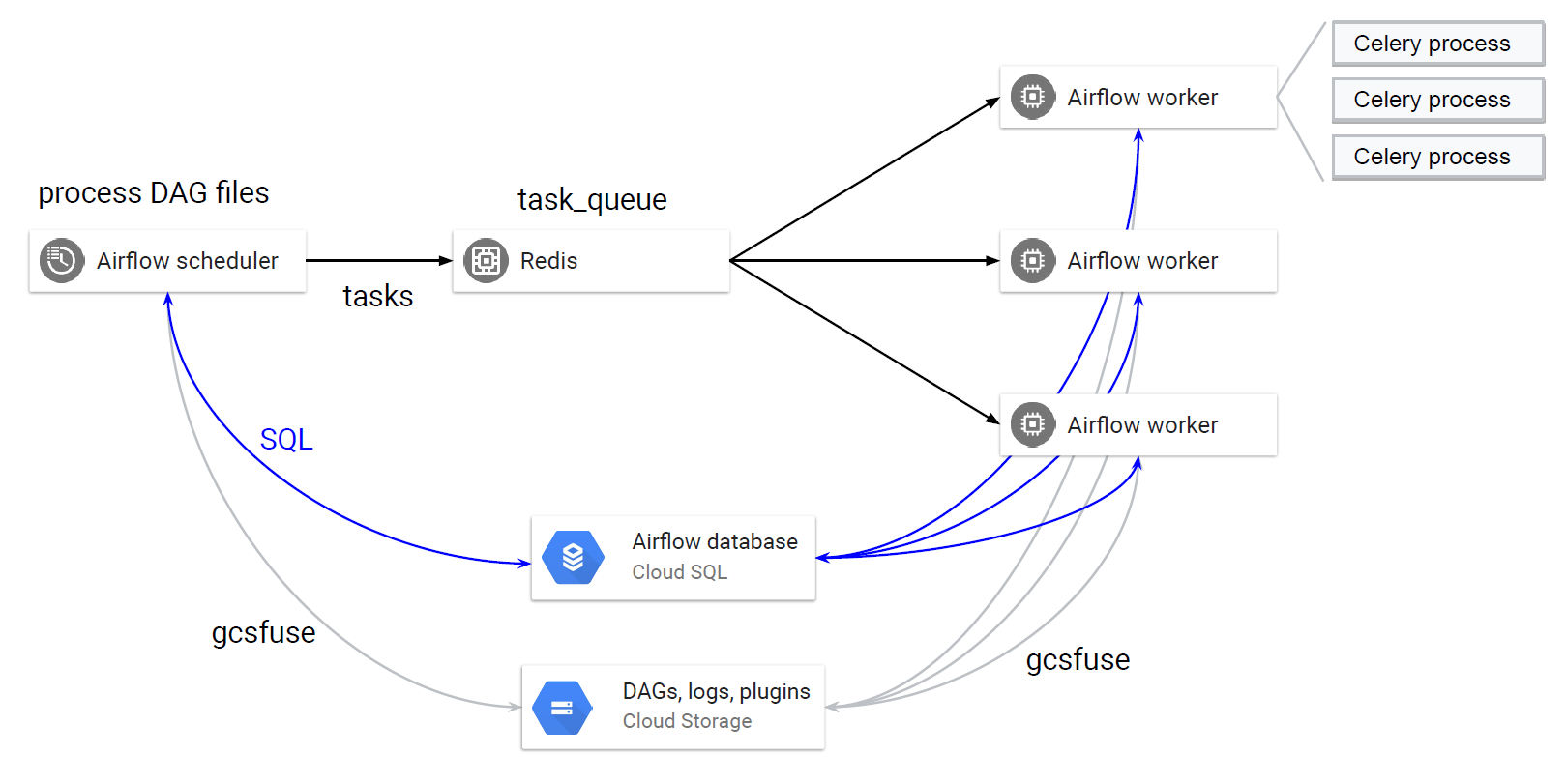
The simplest scheduler is a CRON. On the other hand, for DAG type of workflows, one can use Luigi or Airflow. We started with the simplest model whose output was pushed to a DB with the timestamp and the specific prediction. This pretty much covers all the basic aspects of productizing machine learning.
Machine Learning Operations (MLOps)

This is everything to do with the machine learning system once it’s life and in production. MLOps can be defined as processes, tools and code architecture designed to maintain and improve a machine learning system.
- The outputs can be varying, how do you test for these?
- How to catch for drift in the data and the need for new learning.
- The frequency of training and model performance updation.
- Model performance monitoring and how?
- How to quickly diagnose issues in the system performance.
Each of these is a challenging topic and does not have a ready approach or strategy as of yet. This is an interesting source.