
Numerai is the new age decentralised hedge fund combining the best of blockchain and financial machine learning. As mentioned over their blog, the world of data science competitions has been killed by the relentless pursuit of similar models, created in a similar fashion. Thus the need for something like Numerai.
Given the explosion of data scientists and the availability of fairly robust tools and computing power, it was a matter of time before something like this went more mainstream. Similar attempts in the past such as Quantopian, World Quant have ended though. Numerai seems to be on the upswing. They have over the recent years, heated top-notch funds by quite a margin.

Smart Competition Setup
Fundamentally, the whole structure has a bunch of things going for them which could be a key differentiator for why they might succeed where others have failed.
- Staking: The first and foremost difference is that you stake your own models instead of receiving an allocation. This fundamentally changes the incentive structure. Forcing more discipline and skin in the game for the participants. You bet as per your own conviction on your models.
- No conflict of interest: WorldQuant had internal researchers competing with the outside ones, this makes kinda makes it difficult for the outside models. On the other hand, Numerai is a singular competition with no discrimination.
- Points for Originality: The scoring for the models involves performance and as little correlation or original signal as possible. This is similar to WorldQuant’s way of ranking alpha but was not sure if Quantopian had any such.
All of these make the competition fair, use the concepts of skin in the game and overall gives the project a great chance of success. By creating their own cryptocurrency, for staking purposes, there could not have been a better use for the cryptocurrency.
Competition Metrics
Numerai is a financial data science competition at its heart. So, there are a few metrics to keep track of and understand. The performance and originality of the individual models drive the payout ratios.
The meta-model is a combination of everyone’s models that controls the funds. Thus individual models that improve overall meta-models performance are incentivised.
- Correlation (CORR): This is the typical correlation between predictions and the target. The higher, the value, the better is the performance of the model.
- Meta Model Correlation (MCC): Numerai’s write up is pretty good. It does a job of explaining the process. The gist is to compute, your model’s correlations with others predictions instead of the target. Having little correlation and being different is better.
- Feature Neutral Correlation (FNC): This is also well explained in this document. This metric calculates, the performance as a function of correlation with features. In simple terms, a model relying on more feature sets is better than something which performs because of a few. This metric incentivises stability. A model relying on a large feature set is more stable.
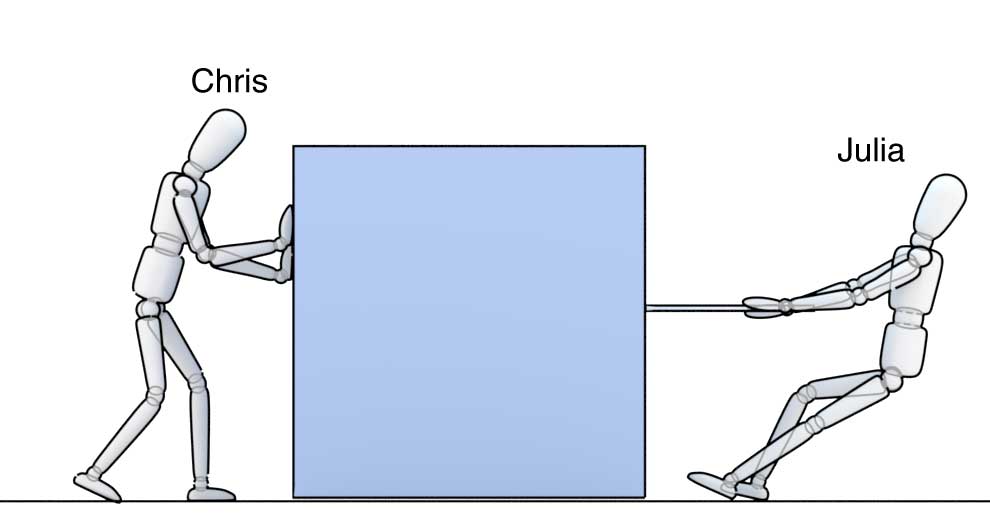
- You want to incentivise forces that move the block in the right direction. Thus correlation or CORR.
- Sometimes, some small forces but orthogonal to other major ones can be useful. So, MCC is used.
Force well spread across the surface is more stable than a concentrated one. The FNC metric gets it

As far as Numerai is concerned, the physics behind the competition checks out fine.
Competition Logistics
The competition runs every week and requires new predictions or submissions either as a part of new model or old ones. The payout factor is computed as a function of the above metrics.
- New tournament or ability to revamp predictions every week.
- Simple and clean starter kit. I was able to put together the environment and make the submission within a day.
- The environment is easy to replicate using the requirement.txt file and creating a separate environment for Numerai alone.
- Numeraire is the currency of the competition. It can be bought like any cryptocurrency.
Data Science Environment Setup
Running a large scale collaborative data science competition and being able to do so, on a week on week basis is a challenge. Thereby requiring a solid combination of good data science and devop practices. Their setup is so good. That, I was quickly able to replicate the environment and made the first submission within a day.
Any firm with a data science function could learn a lot from their data science, DevOps and documentation practices.
- Keep things simple.
- Make it easy for teams to participate and contribute by keeping the core foundation and environment setup easy.
The Setup Steps
The broad steps involved were fairly simple:
- There is a simple starter kit consisting of scripts to replicate with an example script.
- The input training and validation data sets, along with the corresponding tournament data set.
- A clear requirement.txt file for replicating the environment.
- The datasets are in Apache Parquet form to allow for the most efficient storage and consumption of data.
One simply has to download and unzip the files.
- Create a conda/pyenv environment
- Activate it
- Load the environment by installing the requirements.txt file.
- Run the example script to be able to get a feel for the process.
- Upload the diagnostics file to get the output.
A good data science culture would allow for all this to happen within a week maximum.
Happy to connect either through the form below or Calendly Link